
An insight to the revolution of “Big Data” – A Primer
During the 1990s, no one could imagine the pace at which the technology backed by internet will evolve. In 1988-89 hard disk drives of about 100MB storage capacities were sufficient for 386 desktops. In a span of around 10 years, the storage capacity requirement shot up to around 2GB with an increase of around 20X. By the year 2015 users were uncomfortable even with 1TB capacity that is one thousand times increase in 15 years.
According to Prof. Hal Ronald Varian (Chief Economist – Google), 5 EBs (Exabytes) of digital data was created by the human beings till 2000, and these days that much of data is being created in just two days. World’s digital data was near 1 ZB (Zettabytes) in 2010 and by 2020 it would possibly touch 50 ZBs or 50 Trillion GBs (Gigabytes) which means an increase of 50 times.
Is Information explosion responsible for the birth of “Big Data”?
In the era of explosion of digital information, now almost 50% of the world’s population use internet daily. Millions of people browse the internet, send instant messages and share huge amount of data in the form of documents, audios, videos, animations across popular platforms like Facebook, Youtube, Instagram, WhatsApp, Twitter, Reddit, Linkedin and many more.
We
all are responsible for generating huge data every minute;
> 360,000+ Tweets
> 293,000 Facebook status updates
> 510,000 Facebook comments posting
> 45 Million Instant Messages
> 800,000 Google searches
> 300 Million emails sent
> 4500 Terabytes of data creation
> 800 New cell phone users surfing the web
Today “Big Data” is growing day-by-day due to;
1) The prime reason being the data created by each one of us.
2) Availability of high-speed processors day-by-day – shift seen from pocket calculators during the 1990s to high speed personal computers these days.
3) Availability of higher storage capacities – shift seen from few Megabytes of Analog data during the 1990s to Terabytes of Digital data these days.
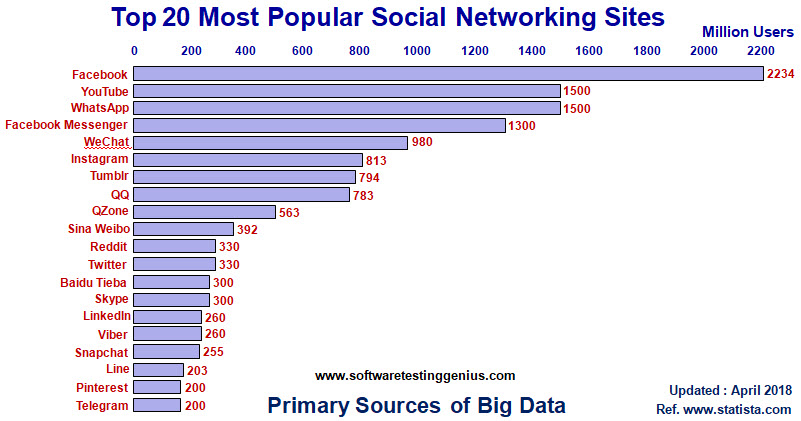
May it be the business environment, or for pleasure’ sake, we keep on generating an ever-increasing amount of digital data in anything we do. World population is 7.6 Billion out of which 6 Billion people are having cell phones. With the digital explosion of information, over 4 Billion people are surfing the web in a quest for information and being connected to the world.
The information being exchanged resides on some machines in digital format like multimedia files, text documents, spreadsheets etc. Smaller data itself takes up the form of “Big Data” when its size fattens from Kilobytes to Terabytes to Zettabytes due to the quality and volume of data.
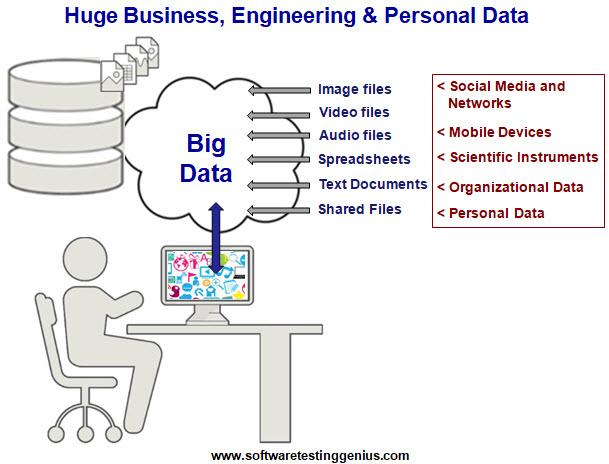
So what is “Big Data”?
It is quite tedious to describe “Big Data” with a single definition, the reason being several IT scientists are still scratching heads in exploring it.
Wikipedia describes “Big data” in simple terms as datasets which are;
1) Voluminous
2) Complex
3) Difficult to process by conventional applications
Today a university scholar says “Big Data” to be the dataset that exceeds one Million GBs or 1Petabyte, however, in near future, this statement may not hold good.
Gartner describes “Big data” as data with 3 typical attributes or 3V’s as;
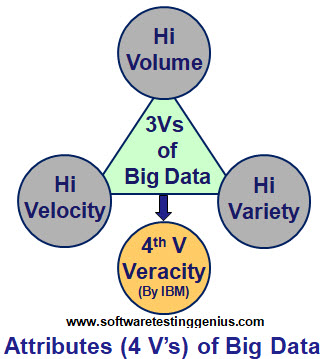
1) High-Volume:
Volume means a virtual shift from Terabytes to Zettabytes in future. It refers to huge amount of data generated by the companies under the fast-paced business environment and which is larger than the capacity of conventional relational database systems to handle. Volume can be judged from the fact that most of the companies in the US have 100 TB of stored data. For instance New York stock exchange itself processes around 1TB of data during every trading session.
2) High-Variety:
Variety refers to a practical shift from structured data to highly unstructured data these days. Right now the challenge is that the data is coming in the variety of formats.

Structured data is quite organized like numeric data in Microsoft Excel spreadsheets and traditional relational databases. Whereas unstructured data is almost everything other than else like financial transactions instant messages, emails, text files, Microsoft Word documents, PPTs, image files, PDFs, audio files, video files, voicemails, and recordings by customer care service. Such unstructured data invariably needs more resources to draw sense out of it.
3) High-Velocity:
Velocity refers to a shift from batch processing to high speed stream processing. Means data that is streaming at an extraordinary speed and is expected to be processed and analyzed in real time. For instance, mobile users expect an instant response (milliseconds to seconds) to any action.
IBM adds another qualitative attribute that is fourth-V (Veracity) to the list.
4) Veracity:
Means trustworthiness of data regarding its accuracy. Poor quality data when processed and used leads to poor decisions and financial losses. Today veracity has become a monstrous challenge for the data scientists.
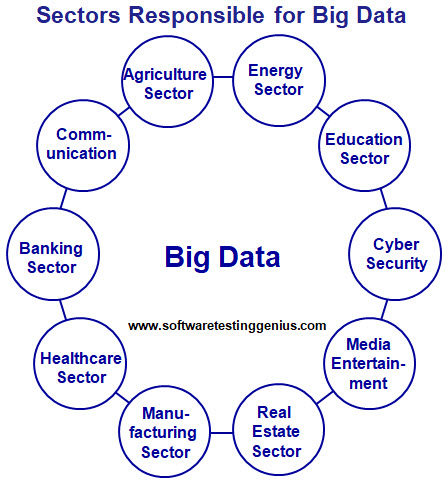
Where does “Big Data” come from?
Various sectors that are responsible for generating “Big Data” are shown below.
The major chunk of “Big Data” comes from three primary sources like;
1) Networks and Social Media:
Every one of us is responsible for generating a huge amount of data every day through social media platforms. We post messages, tweets, re-tweets, likes, comments, upload videos and general media files instantly over popular portals. Public web facility like Google Trends too is responsible for increasing the volume of “Big Data”.
2) Data from Scientific Instruments:
Sensors installed over industrial equipment generate a sizeable amount of information called machine data. Extensive use of sensors like satellites, CC cameras on roads, smart meters, medical devices, games and event logs meant for tracking the user’s behaviour make a large contribution to the machine data. With the growth of “Internet-of-Things” (IoT), such high velocity, high volume and a large variety data is expected to grow exponentially in the future due to an increase in connected nodes.
3) Data from Transactions:
Every minute, users are making online as well as offline business transactions and are generating transactional data. Digital invoices, material delivery receipts, inventory transactions, payment orders are the type of transactional data that becomes huge over a small period.
Challenges coming with “Big Data”:
1) Storage:
The pace at which enormous amount of data to the tune of several Zettabytes (ZBs) is being generated, the biggest technological issue is to scale up the manufacturing of hard drives with that many ZBs of data storing capacity.
2) Return on investment:
The next challenge, for the organizations, with the “Big Data” initiatives shall be the ROI.
3) Quality of Data:
Managing the unstructured, inaccurate, inconsistent and incomplete data remains the key concern for the organizations. US economy suffered an annual dent to the tune of $3 Trillion due to poor quality data.
4) Security of Data:
Due to the enormous size of data, maintaining its security is a big challenge. Security aspects of data are user authentication, permitting limited access to the users, maintaining data access logs and even encryption of data is tedious.
5) Analysis of Data:
For analysing a large volume of data strong algorithms are required to look for patterns and deeper insights into it.
6) Deep Analytical Talent:
For handling sophisticated “Big Data” projects, organizations need experienced data scientists, analysts, developers and software testing engineers with sound domain knowledge. Right now there seems to be a big gap in the demand and the availability of trained manpower.
Many More Articles on – New Technologies – Big Data

An expert on R&D, Online Training and Publishing. He is M.Tech. (Honours) and is a part of the STG team since inception.