
Glossary of Terms related to Big Data-Alphabet A to B
I am giving you a full length repository of definitions in an alphabetically sorted order
1) This database explains various concepts, terms and definitions designed to help communication in the field of Big Data and related disciplines.
2) An effort has been made to make this database quite exhaustive with maximum possible definitions & terms exclusively related to Big Data. These definitions & terms explained by several experts of Software Testing field have been included in it.
3) You are most welcome to contribute & tell us the missing terms or definitions & we shall add it here.
Alphabet – A
Algorithm:
Although algorithm is a generic term given to a mathematical formula or statistical process, yet it has been greatly popularised by Big Data analytics. Algorithm is a set of rules given to an “Artificial intelligence and neural networks” or other machines to help it learn on its own. Most popular types are classification, clustering, recommendation, and regression.
Analytics:
Analytics related to “Big
Data” is about making inferences and story-telling with large sets of data. Three types of popular analytics are a “Descriptive Analytics”, “Predictive Analytics” and “Prescriptive Analytics”.
Apache Software Foundation (ASF):
ASF is an American non-profit corporation which is a decentralized open source community of developers engaged in providing many of the Big Data open source projects. The software produced by them is distributed under the terms of the Apache License and is free and open-source software (FOSS).
Apache Drill:
Apache Drill is an open-source software framework which supports data-intensive distributed applications for interactive analysis of large-scale datasets. Drill is focuses on non-relational datastores, like Apache Hadoop text files, NoSQL and cloud storage.
Apache Flink:
Apache Flink is an open source streaming data processing framework from “Apache Software Foundation”. The core of Apache Flink is a distributed streaming dataflow engine written in Java and Scala.
Apache Hadoop:
Apache Hadoop is a collection of open-source software utilities that facilitate using a network of many computers to solve problems involving large amounts of data and computation. It provides a software framework for distributed storage and processing of big data using the MapReduce programming model.
Apache Hive:
Apache Hive is a data warehouse software project built on top of Apache Hadoop for providing data summarization, query and analysis. Hive facilitates reading, writing, and managing large datasets residing in distributed storage using SQL-like interface to query data stored in various databases and file systems. Hive supports analysis of large datasets stored in Hadoop’s HDFS.
Apache Impala:
Apache Impala is an open source massively parallel processing (MPP) SQL query engine for data stored in a computer cluster running Apache Hadoop. Impala is used by data scientists for performing analytics on data stored in Hadoop.
Apache Kafka:
Apache Kafka is a distributed streaming platform (named after famous czech writer) that is used for building real-time data pipelines and streaming apps. It is very quite popular as it enables storing, managing, and processing of streams of data in a fault-tolerant and fast way. It is an improvement over traditional message brokers due to improved throughput, built-in partitioning, replication, latency, and reliability.
Apache Mahout:
Apache Mahout is a project of the Apache Software Foundation to produce free implementations of distributed or scalable machine learning algorithms focused on collaborative filtering, clustering and classification.
Apache NiFi:
Apache NiFi is an open-source Java server that is designed to automate the flow of data between software systems. NiFi is a Java program that runs within a Java virtual machine running on the server it is hosted over.
Apache Oozie:
Apache Oozie is a server-based workflow scheduling system to manage Hadoop jobs. Oozie provides workflow system to schedule and run jobs in a predefined manner and with defined dependencies for Big Data jobs written in languages like pig, MapReduce, and Hive. Oozie is implemented as a Java web application running in a Java servlet container.
Apache Pig:
Apache Pig is a high-level platform for creating programs running on Apache Hadoop. Pig platform analyzes large data sets consisting of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. Structure of Pig programs is suitable for substantial parallelization, thereby enabling them to handle very large data sets. The scripting language for Pig is called “Pig Latin”.
Apache Spark:
Apache Spark is an open-source big data processing engine that provides quick and interactive SQL like interactions with Apache Hadoop data, or Mesos, or the cloud. Spark has as its architectural foundation the resilient distributed dataset (RDD), a read-only multiset of data items distributed over a cluster of machines, that is maintained in a fault-tolerant way.
Apache Sqoop:
Apache Sqoop is a tool for efficiently transferring large amount of data from Hadoop to non-Hadoop data stores like data warehouses and relational databases.
Apache Storm:
Apache Storm is a free and open source real-time distributed computing system written predominantly in the Clojure programming language. It makes it easier to process unstructured data continuously with instantaneous processing, which uses Hadoop. It uses custom created “spouts” and “bolts” to define information sources and manipulations to allow batch, distributed processing of streaming data.
Artificial Intelligence:
Artificial intelligence is a machine’s ability to make decisions and perform tasks that simulate human intelligence and behaviour. It is related to the development of intelligent machines with a combination of software and hardware so that it is able to perceive the environment and can take necessary action as and when required and keeps learning from such actions.
Alphabet – B
Batch Processing:
Batch data processing is an age old technique, yet it has gained more significance due to dealing with large dataset in case of Big Data. Batch data processing is an efficient way of processing high volumes of data where a group of transactions is collected over a period of time.
Behavioral Analytics:
Behavioral analytics are a subset of business analytics which focuses on understanding what consumers and applications do, as well as how and why they act in certain ways when using eCommerce platforms, social media sites, online games, and any other web application. Behavioral analytics understand user’s web surfing patterns, social media interactions, their ecommerce actions, purchasing decisions like choices in shopping carts and connect massive volumes of raw user event data captured during web sessions and attempt to predict logical outcomes.
Big Data:
Big data refers to a common term for the collection of data sets that are complex and large in volume so that it is difficult to process it using conventional database management tools. The flow of data into the system takes place at a high velocity, with large variation, or at high volumes. Big Data requires new ways to store, process, analyze, visualize, and integrate.
Biometrics:
Biometrics is a technological and scientific method to identify people based on biology. Biometric identification authenticates secure entry, data or access via human biological information such as DNA, face recognition, iris recognition, fingerprint recognition etc. Biometrics is used for security systems for ID cards, tokens or PINs. Biometrics systems require a person to be present, which adds a layer of security because other ID types can be stolen, lost or forged.
Blob Storage:
Blob storage is a feature in Microsoft Azure that stores unstructured data in Microsoft’s cloud platform. This data can be accessed from anywhere in the world and can include audio, video and text. Blobs are grouped into “containers” that are tied to user accounts. Blobs can be manipulated with .NET code.
Brontobytes:
A Brontobyte is approximately equal to 1,000 Yottabytes. In other words a Brontobyte is the number of Bytes that is equal to 1 followed by 27 zeroes ! According to the IBM Dictionary of computing, the hard disk space, or data storage space in terms of bytes in decimal notation are described as
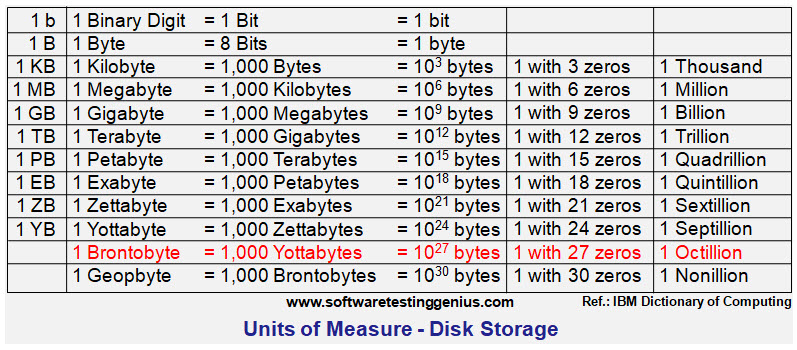
1 Bit = Binary Digit; 8 Bits = 1 Byte; 1000 Bytes = 1 Kilobyte; 1000 Kilobytes = 1 Megabyte; 1000 Megabytes = 1 Gigabyte; 1000 Gigabytes = 1 Terabyte; 1000 Terabytes = 1 Petabyte; 1000 Petabytes = 1 Exabyte; 1000 Exabytes = 1 Zettabyte; 1000 Zettabytes = 1 Yottabyte; 1000 Yottabytes = 1 Brontobyte and 1000 Brontobytes = 1 Geopbyte;
Business Intelligence (BI):
It is a generic term which includes applications, infrastructure and tools, and best practices of visualizing and analyzing business data for the purpose of making actionable and informed decisions for optimized performance.
Continue to Next Part of Glossary of Terms C to D

An expert on R&D, Online Training and Publishing. He is M.Tech. (Honours) and is a part of the STG team since inception.