
Mastering the Art of Writing Intelligent Test Cases Especially for Test Automation
Once the test specification and design are complete and the documents have been reviewed, it is the best time to start building the test cases. Test case design remains the heart of any software testing effort especially for test automation.
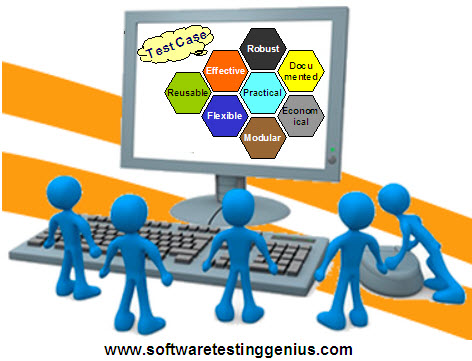
Expert software testing engineers very well know that the reason for putting all this effort into producing well-behaved Test Suites should strike the best possible balance between following fundamental requirements:
1) It must be effective having reasonable probability of detecting errors.
2) It must be practical and must have low redundancy.
3) It must be flexible, structured and maintainable.
4) It must be modular.
5) It must be robust.
6) It must be well documented.
7) It must be built with reusable components.
8) It must be economical having reasonable development cost & ROI.
It is possible to define set of attributes for tests that satisfy the above requirements,
and design the tests according to such attributes.
Every test case must be independent:
Each test case must take care of its own set-up, verification, and cleanup. During the set-up phase, the test case drives the application to a state where the actual test can then be performed. During the verification phase, the actual testing is performed, the results evaluated and a pass/fail status is determined. During the clean-up phase, the set-up is ‘undone’ and the application is returned to a known base state, ready for the next test.
If a test case were to rely on the results of a previous test case, a failure of the upstream test case would most likely cause a failure in the downstream test case. These cascading errors make it difficult to determine what application function was at fault. It also introduces an implied ordering of the test cases: if test case �B� is to be successful, then test case �A� must be executed before it. This ordering is rarely documented, and an innocent reordering of the test case execution in a subsequent test run can cause a long string of failures in a Test Suite that ran perfectly the previous day.
Test cases should be able to execute in any order. This allows a maintainer to pick and choose a subset of the total test cases to execute without having to worry about interdependencies between test cases. In practice, this is somewhat easier said than done. For applications whose functions modify a complex global state, such as an application that reads and writes to a database, beginning from ‘ground-zero’ for each test case would be far too expensive. In such instances, group the test cases together such that each of the groups relies on its own specific pre-existing state to conserve set-up time. Document the interdependencies carefully, so that future main-tamers of the Test Suite will be aware of the dependencies.
Every test case must have a one & only one objective:
A test case should only test one and only one �thing�. This keeps the test case code as short as possible and relatively simple, which makes it easy to understand, debug, and maintain. It also means that there are only two possible outcomes when the test case is executed: pass or fail. Test cases should always do sufficient checking to be able to return a pass/fail status. This makes it easy to determine the outcome of a test run, since no interpretation of the results is necessary.
Single-purpose test cases make it very easy to pinpoint the application function at fault in the event the test case fails. This implies that a Test Suite is comprised of many smaller test cases rather than fewer large ones.
A failed test case should not cause others to fail:
If a test case fails due to an unexpected error, the application is by definition in an unknown state. The application is out of synch with what the test case is expecting. When such failures happen, a well-behaved test will log the failure and abort, and will do a best-effort attempt to reset the application to a known base state.
The software testing tool must be able to isolate the failures of test case in a way that some unexpected mistake in the test case does not become the cause of failure of the entire script. All modern GUI testing tools usually come packed with such functionality.
How a test case should recover from a failure:
There are many things that can cause a test case to fail besides a bug in the AUT. There could be a bug in the test code, an environmental error (e.g. no disk space, network link down), a change made to the application, excessive machine load that causes timing errors, or a host of other reasons.
When an unexpected error occurs, the test case gets out of synch with the state of the application. In case of such an event, we would like the test tool to detect the fact that something is wrong and then do the following:
1) log the fact that there is an error, including trace-back information in the log so that we can tell where the error occurred;
2) Abort the test case, since by definition, the application is in an unknown state;
3) Attempt to get the application back to a known state so that subsequent test case won’t automatically fail. This may include restarting the application after a crash;
4) Resume the execution with the next test case.
All modern GUI test tools have built-in capability to detect an error, log it (with trace-back information), and pick up again with the next test case. The problem that arises is that the application is now in an unknown state, and unless some action is taken to reset the AUT to a known state, subsequent test cases are likely to fail.
Every test case must be well documented:
One of the advantages of writing a detailed test design is that you can take the test case description from the document, put comment characters at the beginning of each line, and use it for header comments in the test case code. Of course, you should also include in-line comments in the code to describe the logic.
Use of test case design techniques:
Apart from using above fundamental requirements of test case deign, test engineers use following test case design techniques to suit their requirements.
1) Specification-Based Techniques
2) Structure-Based Techniques
3) Defect-Based Techniques
4) Experience-Based Testing Techniques
5) Static Analysis
6) Dynamic Analysis
The choice of the test techniques is dependent on the test object, the risks to be mitigated, the knowledge and experience of the software under testing, and the nature of the basis document(s).
There are many advantages of using specialized test design techniques to design the test cases.
Techniques support systematic and meticulous work and make the testing specification effective and efficient; they are also extremely good for finding possible faults. Techniques are the synthesis of �best practice� – not necessarily scientifically based, but based on many testers� experiences.
Other advantages are that others may repeat the design of the test cases, and that it is possible to explain how test cases have been designed using techniques. This makes the test cases much trustworthier than test cases just �picked out of the air.� The test case design techniques are based on models of the system, typically in the form of requirements or design. We can therefore calculate the coverage we are obtaining for the various test design techniques.
Coverage is one of the most important ways to express what is required from our testing activities. It is worth noticing that coverage is always expressed in terms related to a specific test design technique. Having achieved a high coverage using one technique only says something about the testing with that technique, not the complete testing possible for a given object.
Pitfalls of using test case design techniques:
Software testing engineers need to be aware of following pitfalls in using test case design techniques.
1) A common pitfall is in relation to the value sensitivity. Even if we use an input value that gives us the coverage we want it may be a value for which incidental correctness applies. A quick example of this is the fact that:
(2 + 2) equals (2 * 2) however (3 + 3) isn�t equal to (3 * 3)
2) Even if we could obtain 100% coverage of what we set out to cover (be it requirements, or statements, or paths), faults could remain after testing simply because the code does not properly reflect what the users and customers want. Validation of the requirements before we start the dynamic testing can mitigate this risk.
Many more Flambuoyant Articles on Test Design

An expert on R&D, Online Training and Publishing. He is M.Tech. (Honours) and is a part of the STG team since inception.
I want to apply for QTP advanced exam HPO-M98 . Can you please provide the details like sample papers; exam centre details; cost of exam etc as like you provide for other exams