
Winner of Hide and Seek between a Tester and the Bugs during Software Testing
Whether our testing is really able to find bugs or is seeding more of them every time we try to fix them? Is a tricky question. One of the practical way to answer this question is to find out the ration of number of bugs reported by the clients versus number of those found in-house for any release. Although this metric appears quite simple, yet it has a simple drawback that:
1) It ignores the bugs that users don�t report, may be because these are so bad that users feel like abandoning the use of the system or the product.
2) It Is only available when it is no longer useful, some months after the release.
A good substitute for this is to:
1) Identify different indicators like:
# Number of bugs found by testers as a proportion of the whole, average number of bugs found per day.
# Total number of bugs found as a proportion of estimated bugs found
# Priority-1s and priority-2s as a proportion of all the bugs found.
2) Compare them with previous releases and observe the fluctuations.
3) Use a bug-seeding tool to estimate how many bugs remain in the system (when enough of the system has automated all the written tests).
Why We could not detect That Bug Earlier?
When the project completion deadlines come closer & closer, such questions are usually heard.
The concerned personnel find an easy escape through the answers like the following:
1) The testing could not be completed since new release had to be loaded on to the testing personnel.
2) This bug had not been there in the previous release (We need to check the previous release).
3) Since a portion of the previous release could not work properly & the tests could not detect this bug earlier.
4) This bug happened to be in a portion of the system that had not been planned originally for releasing & for that a test has been written recently.
5) This bug had been detected at the time of executing some other set of tests.
6) This bug happened to be in a portion of the system that had been out of the purview of testing.
7) Had the tester executed the particular test, this bug would have been detected for sure.
8) Lastly had the test team been more vigilant, this bug would have been detected earlier as well.
A typical list of bugs found at later stages can be as shown below.
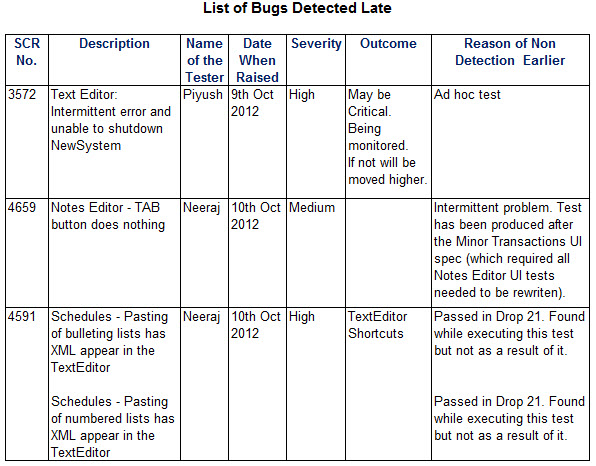
How Many Bugs Are Being Introduced with Each Fix?
It is known as a infinite defect loop. It causes major delays to the development of the product.
Infinite defect loops have many causes, beginning with an inadequate architecture, but persist because of subtle, frequent changes. Software that exhibits this tendency is probably entropic.
To eliminate or minimize this, we can use the popular approach of synch and stabilize generally practiced at Microsoft. To find this out, you will need to look at two sources:
1) The test history: Look at the execution of tests over the last three to four test runs. How many problems have repeatedly recurred? How many tests have found a bug, had it fixed, and had it recur?
2) The configuration management database: Use this to get the data you need to assess requirements and code turmoil.
What Are the Primary Root Causes of Our Bugs?
The obvious answer to this is to look in the mirror. Of course, the root cause of all bugs is human failing. More usefully, a number of other causes can be determined:
1) The process or phase: Is there evidence that an undue number of bugs are deriving in or from some phase? Would they have been found by better unit tests or system tests? Could the bug have been found by a more rigorous review? This is data that can be got from the bug reports. Most root cause analyses of bugs stop here and shouldn�t. (See section 18.10.2.2 for an example of an out-of-control process that generates out-of-control code.)
2) The tool used: yes, a bad workman blames his tools but maybe the compiler gives misleading messages, maybe the development environment is poor, maybe the allegedly reusable code is, er, terrible, maybe the unit testing tool doesn�t cover all the input ranges it promised to. Ask the developers.
3) The people involved: if each developer has a particular area of responsibility, then it shouldn�t be difficult to work out that Fred or Freda is in need of, er, further development.
4) The feature involved: some features are buggier than others (surprise). This too is data, which can be got from the bug reports.
Which Features Are the Most Buggy?
Providing bugs are feature-related this is simple. We can easily prioritize the development effort in bug fixing as well as reviewing where testing effort is best applied (the buggiest features have the greatest number of changes, which often implies the greatest number of newly-introduced bugs).
Beware though that feature “A” may exhibit more bugs than feature “B”, because you have more tests for feature “A”.
Are We Creating More or Fewer Bugs?
This can be determined by:
Relating the number of bugs found per build to the number of changes (creates, updates, and deletes) of each build. Assume 4 builds: A, B, C, and D. If the total number of bugs found in each build is proportional to the number of changes to that build (a large number of changes equates to a large number of bugs, and a small number equates to a small number of bugs), then the release is probably stable. If (measured over a number of builds) the relationship of changes to bugs found is inversely proportional (that is, more bugs are found as the number of changes falls), then you possibly have a problem.
Measuring the number of bugs found in each iteration of each test. Assuming you can run all the tests to completion on each build, how many bugs do the tests find on each build? Is the number growing, fluctuating, or reducing? If it is not reducing overall, then is the number of priority-1 bugs reducing?
However, there are other possibilities. Following Table describes six cases.
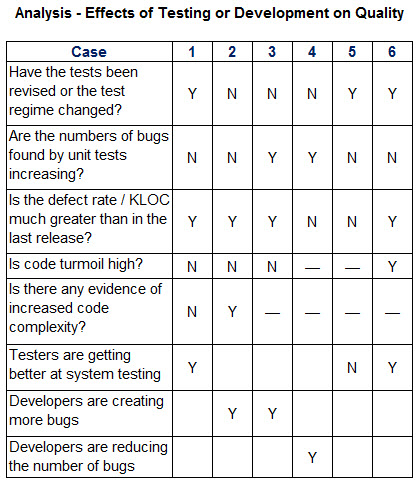
Many More Articles on Software Bugs

An expert on R&D, Online Training and Publishing. He is M.Tech. (Honours) and is a part of the STG team since inception.