
Glossary of Terms related to Big Data-Alphabet E to N
Alphabet – E
Exabytes (EB):
A single Exabyte is approximately equal to 1,000 Petabytes or data stored on approximately 2 million personal computers. 5 Exabytes may be equal to the total number of words ever spoken by human beings so far. In other words a Exabyte is the number of Bytes that is equal to 1 followed by 18 zeroes.
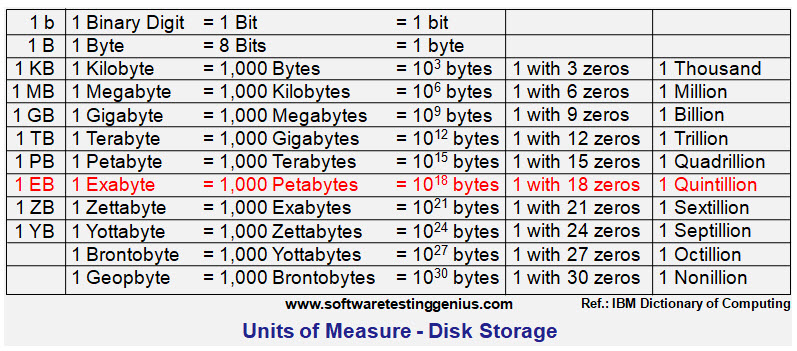
According to the IBM Dictionary of computing, the hard disk space, or data storage space in terms of bytes in decimal notation are described as
1 Bit = Binary Digit; 8 Bits = 1 Byte; 1000 Bytes = 1 Kilobyte; 1000 Kilobytes = 1 Megabyte;
1000 Megabytes = 1 Gigabyte; 1000 Gigabytes = 1 Terabyte; 1000 Terabytes = 1 Petabyte;
1000 Petabytes = 1 Exabyte and 1000 Exabytes = 1 Zettabyte & so on
Alphabet – F
Fuzzy Logic:
Alphabet – G
Gamification:
Geopbytes:
1 Bit = Binary Digit; 8 Bits = 1 Byte; 1000 Bytes = 1 Kilobyte; 1000 Kilobytes = 1 Megabyte; 1000 Megabytes = 1 Gigabyte; 1000 Gigabytes = 1 Terabyte; 1000 Terabytes = 1 Petabyte; 1000 Petabytes = 1 Exabyte; 1000 Exabytes = 1 Zettabyte; 1000 Zettabytes = 1 Yottabyte; 1000 Yottabytes = 1 Brontobyte; 1000 Brontobytes = 1 Geopbyte;
GPU-Accelerated Databases:
Graph Analytics:
Graph Databases:
Alphabet – H
Hadoop:
Hadoop User Experience (Hue):
HANA (High-Performance Analytical Application)
HBase:
HBase is an open-source, non-relational, distributed column-oriented database written in Java. It is a part of Apache Hadoop project and runs on top of HDFS (Hadoop Distributed File System). It offers Google’s Bigtable like functionality to Hadoop. It provides a fault-tolerant way of storing large amount of sparse data.
Alphabet – I
Ingestion:
Alphabet – L
Load Balancing:
Alphabet – M
MapReduce:
Mashup:
Metadata:
MongoDB:
Multi-Dimensional Databases (MDB):
MultiValue Databases:
Munging:
Alphabet – N
Natural Language Processing (NLP):
Neural Network:
Normal Distribution:
Normalizing:
Continue to Next Part of Glossary of Terms P to Z

An expert on R&D, Online Training and Publishing. He is M.Tech. (Honours) and is a part of the STG team since inception.